
Can a fine-tuned GPT-3 write univocalic poems (Eunoia-style)?
Executive summary
I developed a set of computational approaches to help a human (myself) write univocalic poems in the style of Christian Bök’s Eunoia. NOTE, this exercise was for research purposes only. I employed a four different strategies to create these poems:
- Fine-tuning a GPT-3 model on excerpts from Eunoia, and generating dozens of responses from a simple prompt (e.g.
prompt:"Smirking misfits"). - Extracting all univocalic tokens from GPT-2 and using OpenAI’s embeddings to allow for semantic querying (e.g. find a word like “death” with only I’s).
- Post-processing the GPT-3’s output and replacing words which violated the univocalic constraint with the top four suggestions (based on the embeddings).
- A significant amount of elbow grease and human intelligence to create a grammatically acceptable & narratively consistent poem (I estimate ~1 hour per poem on average).
To read all eight univocalic poems (four As, three Es, and one I) produced by this process see this post or jump to the examples below. The code base for this project can be found here.
These computational tools allowed me to produce these poems in a process much faster than I would have been able to do manually. However, the exercise highlighted shortcomings with this framework.
- Despite fine-tuning, a quarter of the words generated by GPT-3 fail the univocalic constraint for sentences with 10 or more words.
- Embedding-related suggestions were the most useful tool during the manual refinement process and suggest expanding the vocabulary beyond GPT-2 tokens (e.g. the Wikipedia corpus, English to non-English dictionaries, etc).
- The sentences produced by GPT-3 tend to be short, full of imaginary words, and rely too heavily on proper nouns to provide bulk.
(1) Introduction
In previous posts I have discussed how to i) fine-tune a GPT-3 model and ii) develop computational tools to support constraint-based poetry creation. This post will bring both of these ideas together and experiment how well a fine-tuned GPT-3 model plus embeddings can support the writing of high-quality univocalic poems. Here is a quick recap on both concepts.
- GPT-3 is OpenAI’s powerful large language model (LLM) that has shown state-of-the-art (SOTA) performance on a variety of natural language tasks. GPT-3 was further refined by OpenAI through a process known as Reinforcement Learning from Human Feedback (RLHF). OpenAI released this model (known as ChatGPT), and the model has (rightly) received significant acclaim.
- A univocalic is a type of constrained writing that requires words only use a single vowel (“A”, “E”, “I”, “O”, or “U”) throughout the entire text. Hence an “A”-based univocalic requires words like: “Adam asks: can Hassan fan a man?” The most celebrated example of a univocalic constrained poetry collection is Christian Bök’s Eunoia.
Excerpt from Chapter E from Christian Bök's Eunoia

Notice that Bök’s poem makes use of non-English words (particularly useful for the letter “E”) as well as other hard and soft rules. I summarize them as follows:
- The letter “Y” counts as a vowel and cannot be used (e.g. “they” is not allowed for an “E”-univocalic).
- Proper nouns are allowed (e.g. Vermeer, Thebes, etc).
- Repeating the same word more than once is generally avoided (except for articles, preposition, and pronouns). However, different conjugations of a base word are not counted as repeats (e.g. sketch, sketches, and sketchers are considered unique).
- The poem should be narratively consistent, grammatically correct, and pleasant to read.
Bök’s poems are beautiful and he spent many years perfecting them. We should not expect a LLM to be able to produce such quality without human intervention. Rather than seeking perfection, the goal of this research exercise was to analyse whether we can develop a set of computational tools that allow a non-expert to write aesthetically competent poems with a univocalic constraint.
The rest of the post structured as follows. Section 2 discusses how to format the data for fine-tuning a GPT-3 model. Section 3 shows the prompts that were used, some of the example output, and the first post-processing adjustments that are done to provide univocalic-consistent suggestions. Section 4 describes how OpenAI’s embeddings for univocalic tokens can help us search for the “right” word. Section 5 provides a qualitative overview to my artistic process for developing the final poems and provides an example from each letter constraint. Section 6 concludes.
Note, I chose to use only three of the five Latin vowels to keep the analysis more tractable. My experience with “I” suggests this was a wise decision as the AI-generated poems deteriorate in quality for the more challenging univocalic constraints (I, O, U).
(2) Data processing and fine-tuning
First, I collected example excepts from Eunoia available online at put them in a data/training.txt file.[1] Second, I extracted all of the tokens from the Hugging Face transformer library: transformers.GPT2TokenizerFast.from_pretrained('gpt2').vocab. I then created a vowel-specific list of tokens and words that would later be embedded. See the 1_process_data.py script for more details.
All unique GPT-2 univocalic tokens are stored for later use
Next, to prepare the data for a fine-tuned GPT-3 model, I simply treated each example excerpt from the training data as a completion, and left the prompt blank. While using blank-prompts is still an open issue with the community, the OpenAI python API does suggest this as a possibility:
Consider leaving the prompts blank if you want to do open-ended generation, otherwise ensure prompts are different.
Since the goal is a stylistic emulation, this seemed reasonable. See 2_prepare_training.py for more details. An example prompt/completion from Eunoia is shown below:
{"prompt":"Univocalic:", "completion":"Awkward grammar appals a craftsman. A Dada bard as daft as Tzara damns stagnant art and scrawls an alpha (a slapdash arc and a backward zag) that mars all stanzas and jams all ballads (what a scandal)."}
Using the output from script #2, I was then able to submit a fine-tuning request for text-davinci-003. See my previous post or OpenAI’s fine-tuning documentation for more information about this process. The fine-tuning process was very cheap, with total cost coming in at about one USD for four epochs (see 3_tune_models.py).[2]
(3) Model prompts and completions
I came up with a list of 40 different two/three-word prompts (14 As, 11 Es, and 15 Is) emulating the type of phrases that were common in Eunoia.[2]
Example of 33 prompts used to generate text

When querying the model, I set max_tokens:172 to approximate the length of the poems seen in Eunoia, "presence_penalty":0.25 & "frequency_penalty":0.25 to limit the repetitiveness of the output, and temperature:[0.8,1] is increased from 0.8 to 1.0 over the repeated queries. Each prompt is queried four times. Below are some examples of the output from the model:



The output of the model is quite unique and I noticed three interesting phenomena.
- The Jabberwocky phenomenon: GPT-3 will string together tokens to make nonsensical words that sound like the style of that Chapter. For example, many of the “A” words are of a Middle Eastern/South Asian origin, and it will produce a word like chanmathar which doesn’t exist, whilst also producing a real word like bhakta.
- The sentences tend to be short.
- The univocalic constraint is almost never consistently applied throughout the sentence.[3]
- The poems lack narrative consistency.
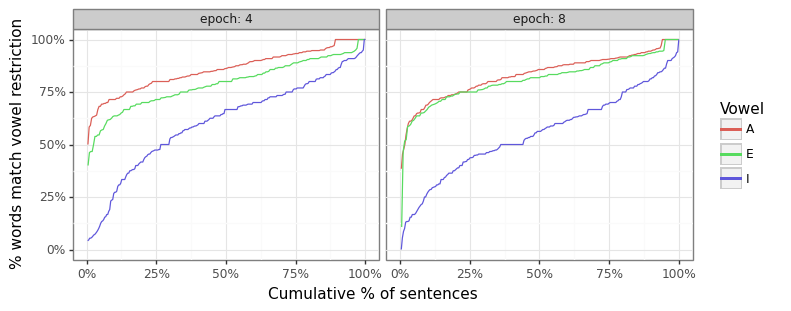
I find that around a quarter (26%) of the words in sentences with 10 or more words fail the univocalic constraint (14%, 20%, and 39% for As, Es, and Is, respectively). Training the model for more epochs marginally improved the distribution for the “E” and “I” vowels as the two figures show below, but is actually deleterious for the “A” vowel so that overall failure rate is similar.
Univocalic distribution is fairly similar across training runs
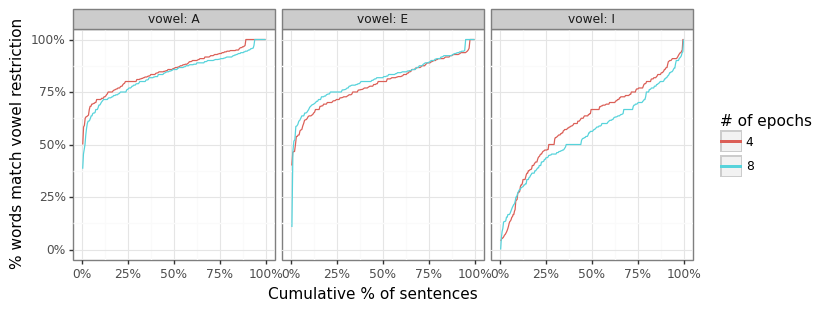
The "I" constraint is harder to maintain
Imitation or emulation?
I wanted to see how close the sentence output was to original training corpus. The table below shows examples of sentences that have the closest Cosine similarity to the original training examples. As we can see, while the results have some similarities, they are sufficiently distint as to indicate that the model has done more than just memorize the poems.
| Vowel | GPT-3 | Training | Cosine |
|---|---|---|---|
| A | A sawman saws apart a logjam and saws as sharp axes saw apart sharp planks and latches | A sawman can hawk all handsaws and hacksaws, all bandsaws and back-saws, sharp saws that saw apart a flat-sawn plank | 0.928 |
| A | Hasan basks at sunbath as a maharajah and, athwart a sand dune, gazes at a phan-tabetic vista: an azure abyss and a scarlet sandbank — an unsurpassed grandeur that can stun an alabastran landmass | Hassan Abd al-Hassad, an Agha Khan, basks at an ashram — a Taj Mahal that has grand parks and grass lawns, all as vast as parklands at Alhambra and Valhalla | 0.908 |
| A | Hasan gags and huffs and haws, and at last gasps — cataracts and spasms, rages and cramps | Hassan gags and has an asthma attack — a catarrh as fatal as lhasa and hanta | 0.895 |
| E | Helen remembers Crete — the green meadows where ewes herd sheep; the steep cliffs where she Fellenz creep | Helen remembers Crete — the Eden where senescent shepherds les bergers des bêtes herd bellwether sheep; there, Helen sees the pebbled steppes the eskers where chert scree bestrews the ledges | 0.939 |
| E | Whenever her regrets depress her, she weeps | She regrets her wretchedness, her dejectedness; nevertheless, she keeps her deepest regrets secret | 0.908 |
| E | Whenever Helen remembers her Greek Erés, she weeps | When she remembers Greece, her seceded demesne, she feels wretched, left here, bereft, her needs never met | 0.904 |
| I | Lightning chills the hills; then the wind whips the froth | Lightning flicks its riding whip, blitzing this night with bright schisms | 0.900 |
| I | I dig in drifted snow, until I find bits of shining glass whence night glimmers — pinpricks twinkle | I dig this ditch, filling bins with dirt, piling it high, sifting it, till I find bright prisms twinkling with glitz | 0.898 |
| I | Hiking sprightly picnics, giggling girls skip hither | Hiking in British districts, I picnic in virgin firths, grinning in mirth with misfit whims, smiling if I find birch twigs, smirking if I find mint sprigs | 0.890 |
(4) Univocalic token embeddings and post-processing adjustments
Section 2 discussed how the univocalic dictionary was assembled using tokens from the GPT-2 model and training excerpts. To be able to recommend constraint-consistent words, I embedded each of these words using OpenAI’s newest embedding model - text-embedding-ada-002 - and then searched for the top 4 words that were found in the univocalic dictionary to the offending word. For example, in the A-output, the word “quack” is generated. The script would embed this word, calculate the Cosine similarity to all A-only words, and then return the top four matches (in this case it is “canard”, “clack”, “jackal”, and “mallard”). For more details see 4_prompt_baseline.py and 5_posthoc_univocalic.py. The figure below shows how this process is done for all offended words in the completion output.
Suggestions are made to model output

(5) Manual work and the finished product
While the output from the fine-tuned GPT-3 provides useful raw material, its lack of narrative consistency and constraint-violations requires a human to invest meaningful creative energy is designing a poem that is aesthetically pleasing. My artistic approach followed a three step process:
- I trawled through the generated output and copied sentence or expressions I thought would be useful to a text file (e.g. “Helen sees the emeralds(egrets-ems-gems-jewels), then grabs(begs-clenches-grebes-greets) the pelf.”).
- I pieced these fragments into different blocks based on topical consistency.
- I manually adjusted the poem, deleting words, and Googling to see which ones were real (e.g. chanmathar (fake), bhakta (real)). When I wanted works to fill gaps, I used an embedding word-search tool (see find_similar_univocalic.py), as the example figure shows below.
Finding "E"-only synonyms for "they", "guards", & "destroy"

I estimate that it took an average of one hour per poem, with the “A” poems being the fastest, and the single “I” poem being the hardest. Three poems are showcased below. See this post to view all eight poems.
"A"-constraint

"E"-constraint

"I"-constraint

(6) Concluding thoughts
I was impressed by the range of vocabulary the fine-tuned GPT-3 model was able to generate, and how it adhered to the qualitative feel of its training examples. However, the output of the model requires substantial human intervention to create a univocalic poem that is artistically competent due to i) a lack of narrative consistency, and ii) common usage of words which violate the constraint. The latter issue could be remedied if GPT-3 was open-source (which won’t happen for commercial reasons), or it allowed users to place restrictions on the tokens that are considered during inference time. Placing restrictions on token-probabilities during inference, whilst keeping the model parameters and structure identical is a method that has been developed by Roush et. al for open source models.
Overall, this exercise furthered my appreciation for how much of an artistic triumph Eunoia is, as well as showcasing the usefulness of AI-generated output combined with queries based on embeddings to allow humans to generate aesthetically pleasing artistic creations.